An intelligent pipeline for every page.
Not one OCR engine. An orchestration of recognition technologies chosen automatically per page — with cryptographic verification linking every extracted value back to the original.
Adaptive Extraction Pipeline
Intelligent processing for every page.
Not one engine. An orchestration of multiple recognition technologies chosen automatically for what each page actually contains.
Document Intelligence
Every incoming page is examined for orientation, resolution, layout family, and content class. The platform normalizes and classifies before a single character is read — so the right downstream engines are chosen automatically.
Adaptive Multi-Engine Recognition
Each page — and each region within it — is routed through the combination of recognition engines best suited to its content. Printed tables, handwritten fields, ink stamps, and mixed content are each handled by the technology purpose-built for them.
AI Escalation
Where confidence falls below threshold, regions are automatically escalated to advanced vision-language AI models for human-level reading — including cursive handwriting, faded ink, and degraded scans.
Verification & Audit Trail
Every original image is preserved byte-identical and cryptographically verified. Every extracted word carries a confidence score and exact coordinate mapping back to the source page. Data you can defend in an audit.
Key Differentiators
Built for evidence, not just extraction.
Byte-Identical Preservation
Original scans are never altered or recompressed. Cryptographic verification proves data integrity for court and audit review.
Multi-Engine Intelligence
Not one OCR engine — an orchestrated combination of recognition technologies chosen per page and per region.
Handwriting-Capable
Handwritten logs, surveyor notes, and physician records that standard OCR platforms consistently fail to read.
Position-Aware Data
Every extracted value links back to its exact coordinates on the source page. Click any field, see the original highlighted.
India Data Residency
Processing on Indian infrastructure available for regulated banking, healthcare, aviation, and public-sector workloads.
Confidence-Scored Output
Know exactly which values are certain and which need human review. No silent errors, no unexplained gaps.
Healthcare Validated
“Extracted from real-world clinical records — one of the most demanding document classes: handwritten prescriptions, lab values in mixed formats, diagnostic impressions, and physician signatures.”
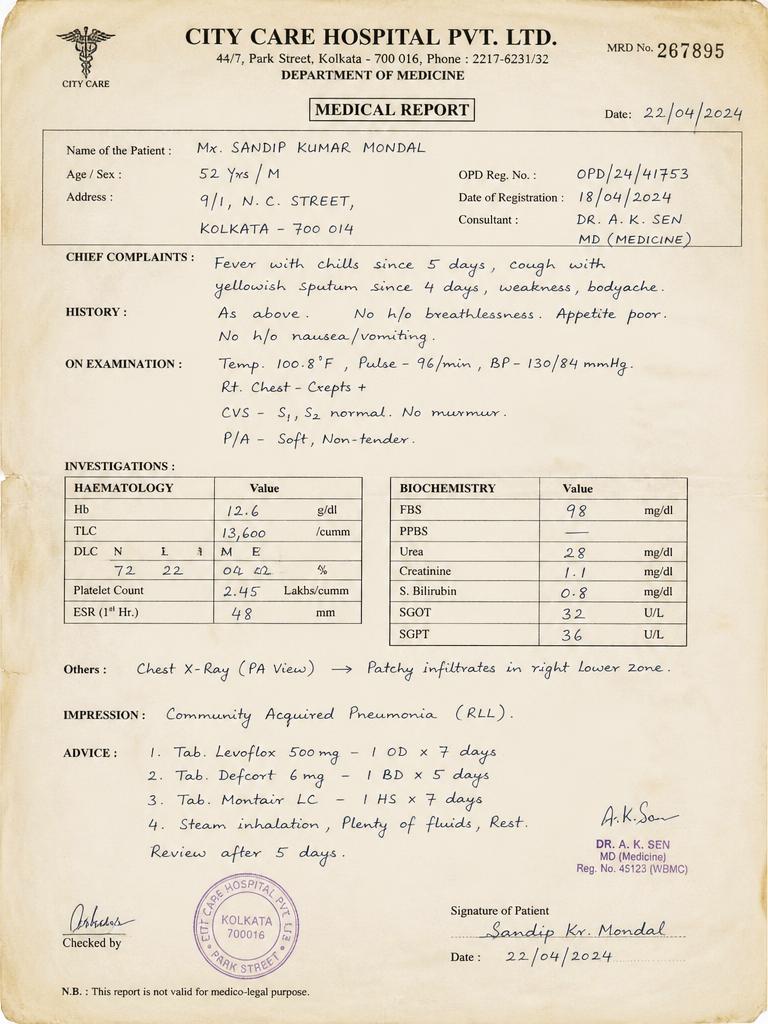
"patient_name": "SANDIP KUMAR MONDAL",
"age": 52,
"diagnosis": "Community Acquired Pneumonia (RLL)",
"hb": 12.6,
"tlc": 13600,
"creatinine": 1.1,
"conf": 0.9947
}
Send us 50 pages of your hardest documents.
See verifiable results — handwriting, stamps, degraded scans — before you commit to anything.